Content plays a significant role with named entities and Chrome Data as potential factors
Google's search ranking algorithm is revealed in leaked documents
Link diversity and relevance are key considerations for links
Links, content, and user interactions are important ranking factors
Google's closely guarded search ranking algorithm has been the subject of much speculation and debate in the tech industry. Recently, a leak of internal Google documents sheds new light on how the company determines which websites rank at the top of its search engine results.
According to multiple sources, including The Verge, Content at Scale AI blog, and Search Engine Land, thousands of leaked Google API documents were published online revealing information about content, links, and user interactions in Google's ranking algorithm. Some features mentioned in the documents may be ranking factors but their weighting in Google's ranking system is unknown.
The leaked documents suggest that links remain an important factor in Google's ranking algorithm, with link diversity and relevance being key considerations. Content also plays a significant role, as named entities and Chrome Data are mentioned as potential factors.
Google has not yet commented on the authenticity of the leak or provided any official statement regarding the contents of the documents. However, some industry experts have analyzed the information and shared their findings with various media outlets.
The SEO community is closely watching this development as it could potentially lead to new strategies for optimizing websites for search engines. It's important to note that while these documents offer valuable insights, they do not necessarily reveal the complete picture of Google's ranking algorithm.
An explosive leak of internal Google documents offers an unprecedented look into how Google Search works.
Rand Fishkin received 2,500 pages of documents from a source with the intention of reporting on the leak.
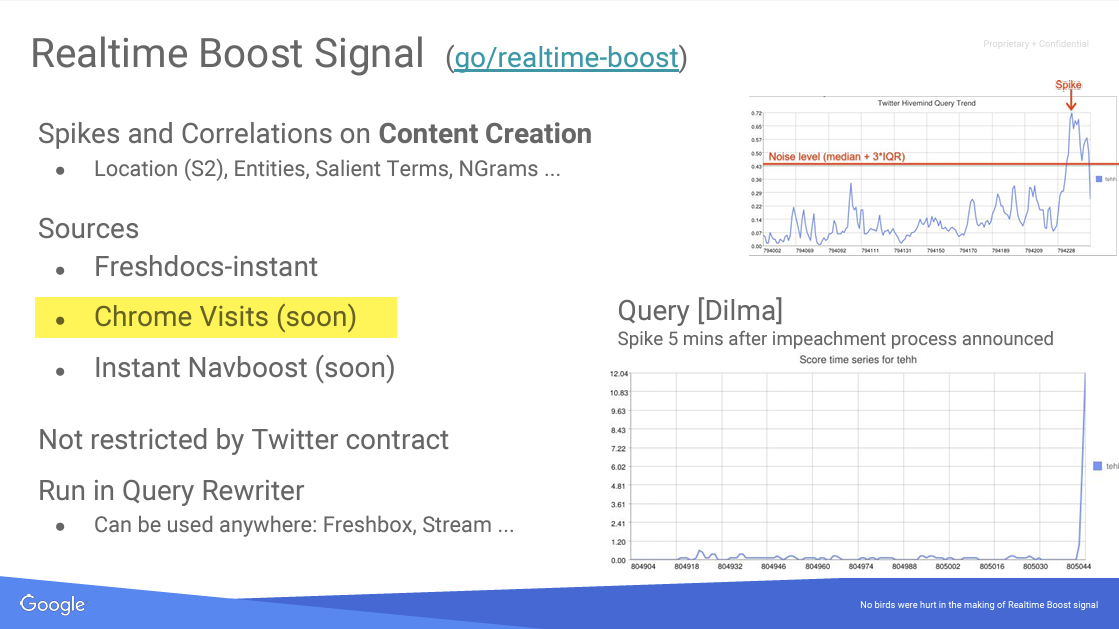
Some details in the documents call into question Google’s public statements regarding whether Chrome data is used in ranking or if E-E-A-T is a ranking factor.
Google representatives have previously said that author bylines are something website owners should do for readers and not Google because it doesn’t impact rankings.
Historically, some publications have uncritically repeated Google’s public statements as truth without further analysis.
Accuracy
Google's search algorithm is a mystery, dictating what sites live and die on the internet.
Google has not responded to requests for comment on the legitimacy of the documents or refuted their claims.
Google collects data that may be used in its search ranking algorithm, including clicks and Chrome user data.
Deception
(30%)
The article contains selective reporting and sensationalism. The author quotes Rand Fishkin stating that the leaked documents suggest Google hasn't been truthful about its search algorithm for years. However, the author also acknowledges that the documents do not necessarily prove that Google uses specific data for search rankings and that some information in the documents appears to be in conflict with public statements by Google representatives. The author then goes on to provide examples of potential deception, such as Google's use of Chrome data and E-E-A-T, but does not provide enough evidence to definitively prove these claims. Additionally, the author uses emotional manipulation by stating that 'Lied' is the only accurate word to use regarding Google's public statements and that some details in the leaked documents call into question the accuracy of Google's public statements. The article also contains sensationalism through phrases like 'explosive leak', 'unprecedented look under the hood', and 'offers an unprecedented look under the hood'.
Google representatives have repeatedly indicated that it doesn’t use Chrome data to rank pages, but Chrome is specifically mentioned in sections about how websites appear in Search.
The documents outline Google’s search API and break down what information is available to employees, according to Fishkin.
Though this doesn’t confirm that bylines are an explicit ranking metric, it does show that Google is at least keeping track of this attribute.
Fallacies
(90%)
The article contains some inflammatory rhetoric and appeals to authority but no formal or informal fallacies were identified. The author makes strong claims about Google's potential dishonesty and manipulation of search algorithms without providing direct evidence, relying instead on leaked documents whose authenticity has not been confirmed. The author also appeals to the authority of Rand Fishkin and Mike King, who have analyzed the leaked documents.
] Google’s secretive search algorithm has birthed an entire industry of marketers who closely follow Google’s public guidance and execute it for millions of companies around the world. The pervasive, often annoying tactics have led to a general narrative that Google Search results are getting worse, crowded with junk that website operators feel required to produce to have their sites seen. In response to The Verge’s past reporting on the SEO-driven tactics, Google representatives often fall back to a familiar defense: that’s not what the Google guidelines say. But some details in the leaked documents call into question the accuracy of Google’s public statements regarding how Search works.
The US government’s antitrust case against Google — which revolves around Search — has also led to internal documentation becoming public, offering further insights into how the company’s main product works.
Bias
(80%)
The author Mia Sato uses language that depicts Google as being untruthful and not entirely transparent about its search algorithm. She quotes Rand Fishkin and Mike King stating that the leaked documents suggest Google hasn't been truthful for years and that some information in the documents appears to be in conflict with public statements by Google representatives.
Some information in the documents appears to be in conflict with public statements by Google representatives.
The details shared by Fishkin are dense and technical, likely more legible to developers and SEO experts than the layperson. The contents of the leak are also not necessarily proof that Google uses the specific data and signals it mentions for search rankings. Rather, the leak outlines what data Google collects from webpages, sites, and searchers and offers indirect hints to SEO experts about what Google seems to care about.
The documents outline Google’s search API and break down what information is available to employees. The details shared by Fishkin are dense and technical, likely more legible to developers and SEO experts than the layperson. The contents of the leak are also not necessarily proof that Google uses the specific data and signals it mentions for search rankings.
The leaked documents call into question the accuracy of Google’s public statements regarding how Search works.
Thousands of leaked Google documents provide insights into Google Search ranking algorithm
Google uses 2,596 modules for ranking with 14,014 attributes
Twiddlers can adjust document scoring or change ranking position
Content can be demoted for various reasons including link mismatch and user dissatisfaction
Google keeps a copy of every version of indexed pages but only uses last 20 changes for analysis
Links remain important factor in Google’s ranking algorithm, with link diversity and relevance key considerations
Accuracy
No Contradictions at Time
Of
Publication
Deception
(50%)
The article contains several instances of selective reporting and sensationalism. The author quotes Rand Fishkin stating that the Google document leak will likely be one of the biggest stories in SEO history, but does not provide any context or evidence to support this claim. The author also states that 'This Google document leak? It will likely be one of the biggest stories in the history of SEO and Google Search.', again without providing any evidence or context. Additionally, the author quotes Michael King stating that 'you need to drive more successful clicks using a broader set of queries and earn more link diversity if you want to continue to rank.' This statement is selectively reported as it only presents part of King's analysis and does not provide the full context of his reasoning.
This Google document leak? It will likely be one of the biggest stories in the history of SEO and Google Search.
you need to drive more successful clicks using a broader set of queries and earn more link diversity if you want to continue to rank.
What happened. Thousands of documents, which appear to come from Google’s internal Content API Warehouse, were released March 13 on Github by an automated bot called yoshi-code-bot. These documents were shared with Rand Fishkin, SparkToro co-founder, earlier this month.
A trove of documents describing Google’s ranking system for search results leaked online.
The leak appears to be the result of an accidental publication by an in-house bot.
The material was committed to a publicly accessible Google-owned repository on GitHub and included an Apache 2.0 open source license.
The documents reveal differences from public statements made by Google representatives about their ranking algorithm.
Google has advised everyone to be aware that the accidentally revealed files may be missing vital context and not to make assumptions based on out-of-context or incomplete information.
Accuracy
Some details in the documents call into question Google’s public statements regarding whether Chrome data is used in ranking or if E-E-A-T is a ranking factor.
Deception
(30%)
The article contains selective reporting as the author quotes and focuses on certain details from the leaked documents that contradict Google's public statements, while ignoring other information that may not support their position. The author also uses emotional manipulation by implying that SEO consultants believe the documents contain 'noteworthy details' because they contradict Google's public statements.
iPullRank’s King, in his post on the documents, pointed to a statement made by Google search advocate John Mueller, who said in a video that ‘we don’t have anything like a website authority score’ ...
Many of [Azimi’s] claims [in an email describing the leak] directly contradict public statements made by Googlers over the years, in particular the company’s repeated denial that click-centric user signals are employed...
The leaked documentation includes numerous references to internal systems and projects... Among the 2,500-plus pages of documentation, assembled for easy perusal here, there are details on more than 14,000 attributes accessible or associated with the API... It is therefore hard to discern the weight Google applies to the attributes in its search result ranking algorithm.
Fallacies
(80%)
The author makes several statements that imply Google's internal practices and contradict previous public statements made by Google representatives. This is an example of an appeal to authority fallacy as the author is presenting information from leaked documents as fact, despite it being against previous official statements. Additionally, there are instances of inflammatory rhetoric used in the article such as 'sparking SEO frenzy' and 'Google goes shopping for Indian e-commerce dominance ... at Walmart'. These do not add any value to the analysis and detract from the overall quality of the article.
][SparkToro]'s Fishkin in a report... Many of [Azimi]'s claims directly contradict public statements made by Googlers over the years, in particular the company’s repeated denial that click-centric user signals are employed, denial that subdomains are considered separately in rankings, denials of a sandbox for newer websites, denials that a domain’s age is collected or considered, and more.[/
Bias
(80%)
The author Thomas Claburn reports on the leak of internal Google documents that describe how Google ranks search results. He mentions that SEO consultants believe the documents contain noteworthy details because they differ from public statements made by Google representatives. The author also points out several discrepancies between the leaked information and previous denials made by Google, such as their denial of using click-centric user signals, subdomains being considered separately in rankings, and a sandbox for newer websites. These discrepancies suggest a potential bias towards providing more detailed and accurate information to insiders or those with access to internal documents over the general public.
iPullRank’s King points to a statement made by Google search advocate John Mueller, who said in a video that ‘we don’t have anything like a website authority score’. But King notes that the docs reveal that as part of the Compressed Quality Signals Google stores for documents, a ‘siteAuthority’ score can be calculated.
Many of [Azimi’s] claims directly contradict public statements made by Googlers over the years, in particular the company’s repeated denial that click-centric user signals are employed, denial that subdomains are considered separately in rankings, denials of a sandbox for newer websites, and more.
/cdn.vox-cdn.com/uploads/chorus_asset/file/24016887/STK093_Google_02.jpg)


:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25467524/Screenshot_2024_05_28_at_9.33.43_AM.png)
/cdn.vox-cdn.com/uploads/chorus_asset/file/24016883/STK093_Google_06.jpg)